Microsoft Computer Vision API - C# Kullanarak OCR
Microsoft yakın zamanda geliştirici konferansında Cognitive Services adı altında bir dizi hizmet paketini kullanıma açmıştı. Bu hizmet paketleri içerisinde görüntü işleme, ses işleme, derin öğrenme, metin işleme ve ekstra arama hizmetleri gibi çeşitli servisler yer almaktadır. Sağlanan bu hizmetlerin bir çoğunu bulut üzerinden sunmaktadır ve belirli bir işlem hacmine kadar ücretsizdir. Değineceğimiz OCR ve diğer servisleri, ticari projelerde veya çok fazla işlemeye ihtiyaç duyulan projelerde satın almanızı öneririm.
OCR Optical character recognition kelimelerinin kısaltmasıdır yani optik karakter tanıma olarak dilimize çevrilmektedir. Bir görsel veya metinsel halde olmayan dokümanı metin olarak elde etmeye yarayan yöntemdir. Bu bağlamda bir çok algoritma mevcut ve bu farklı algoritmaları kullanan ücretli veya ücretsiz bir çok kütüphane, servis bulunmaktadır. Açık kaynak kodlu ve ücretsiz bir kütüphane olan tesseract çok fazla kullanılan OCR kütüphanelerinden birisidir.
Bu yazımızda Microsoft’un hizmeti olan Microsoft Computer Vision API ile gelen OCR hizmetini kullanacağız. Microsoft bu hizmeti AZURE üzerinde yer alan Web Servisi ile veriyor. Yani OCR işlemleri için sürekli olarak bir web servisine istekte bulunacak ve bize gelen JSON veriyi parçalayarak ayrıştıracağız. Daha önce web servislerini kullanmadıysanız endişelenmeyin Microsoft kullanımı oldukça kolaylaştıran açık kaynak kod bir kütüphanede geliştirmiştir. İki yöntemide kullanarak görsellerimize ocr işlemi uygulayacağız. Tüm bu hizmetleri kullanabilmek için bir API anahtarına ihtiyacımız var, bu anahtar ile web servisi erişimini sağlayacağız. API key almak için buradaki https://www.microsoft.com/cognitive-services/en-US/subscriptions bağlantıda yer alan Microsoft’un sitesine giderek öncelikle oturum açıp daha sonra Computer Vision hizmetinden bir api anahtarı üreteceğiz. Satın alma ve kalan/kullanılan hizmet miktarı gibi bilgiler bu site üzerinden görüntülenmektedir.

Bu OCR servisini online olarak denemek isterseniz buradakive buradaki bağlantıya göz atabilirsiniz.
Şimdi projelerimizde nasıl kullanabileceğimize bakalım. Bunun için 2 yöntem olduğunu söylemiştik, ilk Microsfot’un açık kaynak olarak geliştirdiği ara bir katman olan kütüphaneyi kullanmak bir diğeri ise doğrudan web servisine istekte bulunmak ve gelen veriyi parçalamak.
Yöntemlere geçmeden önce bu OCR hizmetinin bir takım özelliklerine göz atalım.
Bu OCR hizmeti otomatik dil tanıma ve aşağıda yer alan dilleri desteklemektedir.
- unk (Otomatik dil tanıma)
- zh-Hans (Chinese Simplified)
- zh-Hant (Chinese Traditional)
- cs (Czech)
- da (Danish)
- nl (Dutch)
- en (English)
- fi (Finnish)
- fr (French)
- de (German)
- el (Greek)
- hu (Hungarian)
- it (Italian)
- Ja (Japanese)
- ko (Korean)
- nb (Norwegian)
- pl (Polish)
- pt (Portuguese,
- ru (Russian)
- es (Spanish)
- sv (Swedish)
- tr (Turkish)
Geniş dil desteğinin yanında, paragraf, ve satır tespiti yapabilmekte bunun yanı sıra istenilen kelimenin koordinatlarını verebilmektedir. Otomatik olarak kullanılan görselin hizalanmasını yapabilmektedir, bu sayede farklı açılardan çekilen görselleri doğru bir şekilde tanımlaya bilmektedir.
1. Yöntem
Microsoft’un geliştirdiği kütüphanenin kaynak kodlarını buradaki https://github.com/Microsoft/ProjectOxford-ClientSDK/tree/master/Vision/Windows/ClientLibrary bağlantıdan indirebilirsiniz. İndirdiğiniz kaynak kodu Visual Studio ile açın ve derleyin derleme sonucunda oluşan Microsoft.ProjectOxford.Vision.dll kütüphanesi hizmetleri kullanmamızı sağlayacak. Sadece OCR için değil sağlanan tüm Vision hizmetleri için bu kütüphaneyi kullanabilirsiniz. Oluşan Microsoft.ProjectOxford.Vision kütüphanesini ve derleme dizininde yer alan Newtonsoft.Json kütüphanesini projemize referans olarak ekliyoruz. Newtonsoft.Json.dll kütüphanesi ise Microsoft.ProjectOxford.Vision kütüphanesinin JSON parçalama (json parsing) için ihtiyaç duyduğu bir kütüphanedir, bu yüzden bu kütüphaneyi de referanslarımıza ekliyoruz.
Şimdi uygulamamızı geliştirmeye başlayalım. Örnek olarak İnternet’ten bulduğum bir görseli kullanacağım, bu görsel bir kitap sayfasından çok da doğru bir açıyla çekilmemiş ve üzerinde bir takım vurgulamalar için çizim yapılmış bir görsel.

Referanslarımızı da ekledikten sonra örnek uygulamayı geliştirmeye başlayabiliriz. Bunun için öncelikle asinkron bir metot yazalım ve parametre olarak vereceğimiz API KEY ve resim adresini kullanarak bize sonuç döndürsün.
private async Task<OcrResults> OCRimageFromURL(string imageUrl, string API_KEY)
{
//İstemciyi oluştur
VisionServiceClient VisionServiceClient = new VisionServiceClient(API_KEY);
//OcrResults nesnesi alanlar,satırlar ve kelimeleri barındırır
OcrResults ocrResults = await VisionServiceClient.RecognizeTextAsync(imageUrl, "tr", true);
return ocrResults;
}
RecognizeTextAsync metodunun farklı overload’ları mevcutur, parametre olarak resim adresini veya byte dizisi (stream) olarak almaktadırlar. “tr” olarak verdiğim string hedeflediğimiz dili belirtmektedir dillerin kısaltmalarını yukarıda yer alan dil listesinden görebilirsiniz, hedef dili bilmiyorsanız otomatik bulması için “unk” (unknown) kısaltmasını kullanabilirsiniz. true olarak belirttiğimiz üçüncü parametre ise kullanılan görselde ki yönün otomatik olarak düzeltilip düzeltilmeyeceğini belirtmektedir. Görselinizin yönünün doğru olduğundan eminseniz performans için false olarak belirleyebilirsiniz. İşlemin nasıl gerçekleştiğini aşağıdaki görsel ile ifade edebiliriz.
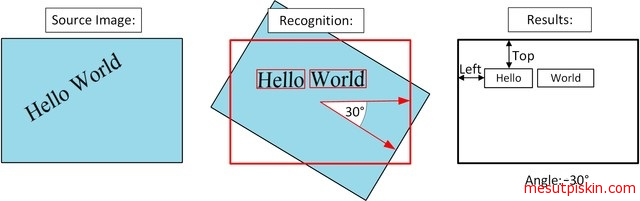
Görsel kaynağı: projectoxford.ai
Şimdi yazdığımız metodu çağıralım ve OcrResult nesnesi içerisinden OCR edilmiş metni çıkartalım.
public async void Doit()
{
OcrResults result = await OCRimageFromURL("/blog/ocr_gorsel.jpg","API_KEY" );
//OCR alanı
foreach (Region region in result.Regions)
{
//Geçerli alan içerisindeki satırlar
foreach (Line line in region.Lines)
{
//Geçerli satır içerisindeki kelimeler
foreach (Word word in line.Words)
{
Console.Write(word.Text + " ");
//Kelime sonu
}
//Satır sonu
Console.WriteLine("");
}
//Bölge sonu
}
OcrResult nesnesinin satır ve kelimeleri barındırdığını söylemiştik, bu yüzden bulunan tüm satırlar içerisindeki tüm kelimeleri dolaşarak yazdırıyoruz.
Sonuç olarak OCR işlemini başarı ile gerçekleştiriyoruz.
2. Yöntem
Bu yöntemle ise doğrudan web servisi isteği yaparak sonuca ulaşabiliriz. Web servisinin adresi: ]. Dil kısaltmalarını daha önce belirtmiştik. İstek için geri dönüş json verisi örneği aşağıdaki gibi olacaktır. Web servisine nasıl istekte bulunurum diyorsanız projectoxford tarafından paylaşılan bu yazıya göz atabilirsiniz. Java ve Python başta olmak üzere bir çok dil için bu işlemin nasıl yapıldığına göz atabilirsiniz.
{
"language": "en",
"textAngle": 0,
"orientation": "Up",
"regions": [
{
"boundingBox": "81,63,1340,1055",
"lines": [
{
"boundingBox": "321,63,855,117",
"words": [
{
"boundingBox": "321,63,174,94",
"text": "Set"
},
{
"boundingBox": "529,87,126,69",
"text": "an"
},
{
"boundingBox": "693,65,483,115",
"text": "example."
}
]
},
{
"boundingBox": "218,182,1059,116",
"words": [
{
"boundingBox": "218,182,271,92",
"text": "Treat"
},
{
"boundingBox": "521,203,504,95",
"text": "everyOne"
},
{
"boundingBox": "1054,182,223,91",
"text": "With"
}
]
},
{
"boundingBox": "156,299,1187,116",
"words": [
{
"boundingBox": "156,299,489,92",
"text": "kindness"
},
{
"boundingBox": "680,299,197,92",
"text": "and"
},
{
"boundingBox": "919,305,424,110",
"text": "respect,"
}
]
},
{
"boundingBox": "81,417,1340,91",
"words": [
{
"boundingBox": "81,438,255,70",
"text": "even"
},
{
"boundingBox": "372,417,307,91",
"text": "those"
},
{
"boundingBox": "708,417,229,91",
"text": "who"
},
{
"boundingBox": "972,438,171,70",
"text": "are"
},
{
"boundingBox": "1178,417,243,91",
"text": "rude"
}
]
},
{
"boundingBox": "182,534,1137,116",
"words": [
{
"boundingBox": "182,539,105,86",
"text": "to"
},
{
"boundingBox": "320,555,198,95",
"text": "you"
},
{
"boundingBox": "553,582,69,14",
"text": "—"
},
{
"boundingBox": "656,539,170,86",
"text": "not"
},
{
"boundingBox": "863,534,456,92",
"text": "because"
}
]
},
{
"boundingBox": "282,651,934,116",
"words": [
{
"boundingBox": "282,652,236,115",
"text": "they"
},
{
"boundingBox": "550,673,171,70",
"text": "are"
},
{
"boundingBox": "756,651,247,111",
"text": "nice,"
},
{
"boundingBox": "1045,651,171,91",
"text": "but"
}
]
},
{
"boundingBox": "292,769,916,116",
"words": [
{
"boundingBox": "292,769,455,91",
"text": "because"
},
{
"boundingBox": "777,790,198,95",
"text": "you"
},
{
"boundingBox": "1014,790,194,70",
"text": "are."
}
]
},
{
"boundingBox": "487,1002,526,116",
"words": [
{
"boundingBox": "487,1002,236,116",
"text": "Spiril"
},
{
"boundingBox": "741,1014,272,67",
"text": "Science"
}
]
}
]
}
]
}