-
Giriş
-
Veri Girişi
-
Veri Ön İşleme
-
Öznitelik
-
Tanımlama
-
1.Giriş
Nesne tespiti ve nesne tanıma uzun zamandır bilgisayarlı görü uygulamaları için vazgeçilmez bir ihtiyaçtı. Yıllardır üzerinde çalışan bu konu için farklı algoritmalar geliştirildi fakat devrim niteliğindeki algoritma 2o01 yılında Paul Viola ve Michael Jones tarafından geliştirilen Viola Jones algoritması oldu. Bu algoritma “Rapid Object Detection using a Boosted Cascade of Simple Features” başlıklı makale ile duyuruldu. Takip eden süreçte bir çok algoritma geliştirildi. Yakın zamanda ise kullanılmaya başlayan GPU teknolojisi ile hız kazanan derin öğrenme sayesinde çok daha fazla doğruluk oranı ile tanımlama yapabilen yöntemler geliştirildi.
Bu yazıda ise nesne tespit ve tanıma süreçlerini 5 ana başlık altında inceleyeceğiz. Veri girişi, veri ön işleme ve aşamaları, öznitelik çıkarımı ve öz nitelik seçimi son olarak ise tanımlama olarak adlandırdığımız veri sınıflandırma aşamalarını göreceğiz. Bu süreçler aşağıdaki görsel de özetlenmiştir.
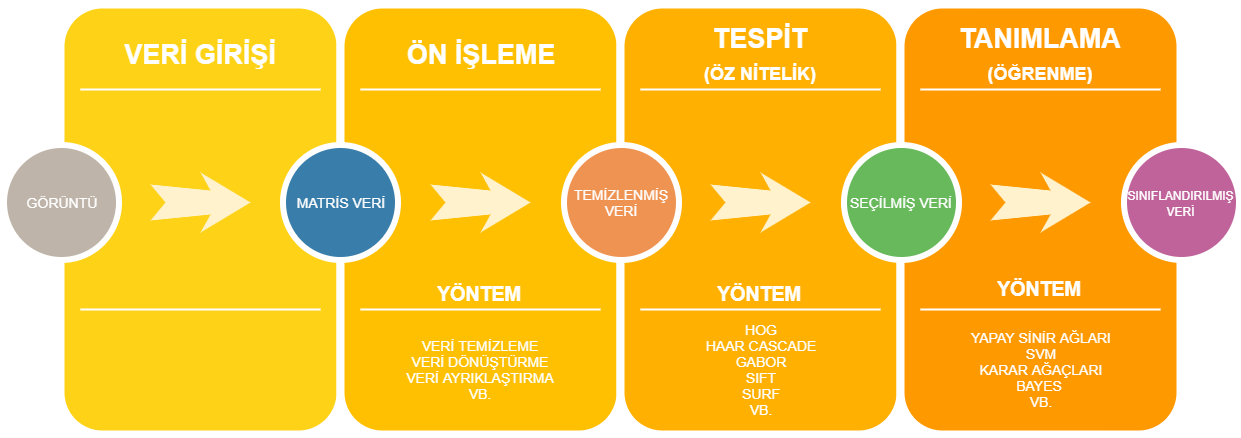 Nesne tespit ve tanımlama aşamaları.
Nesne tespit ve tanımlama aşamaları.
2.Veri Girişi
Bu aşmada hazırlanan veri gürültülerinden ayrıştırılmak, istenilen formata getirilmek gibi amaçlara sisteme girdi olarak verilir. Nesne tespit veya sınıflandırma işlemi yapacağımız için verilerimiz de doğal olarak görüntü olacaktır. Bir insan, otomobil veya ev istediğimiz veriye örnekken, üzerinde insan bulunan bir orman fotoğrafı girdi olarak tanımlanabilir. Fotoğraf makineleri ile çekilmiş fotoğraflar, dijital olarak oluşturulmuş resimler, video filmler ve taranmış metinler bu veri türlerine örnektir. Veri formatı kullanılan teknolojiye, dile, platforma vb. bir çok etkene bağlıdır fakat kullanacağımız algoritmalar için geçerli format matris haline getirilmiş görüntü pikselleridir.
 Örnek bir girdi
Örnek bir girdi
 İstenilen örnek bir veri
İstenilen örnek bir veri
3.Ön işleme
Verilerin yapılacak olan işlemin amacına uygun hale gelmesi için hazırlamak veya engel teşkil etmesinin önüne geçmek için uygulanan bir takım sabit olmayan yöntemlerdir. Sabit olmayan diyorum çünkü ön işlem süreçleri veriye, istere, duruma ortama gibi bir çok farklı etmene göre değişebilen genellikle önceden bilinemeyen, deneyle, deme yanılma ile karar verilen yöntemlerdir. Daha somut bir örnekle açıklayalım; Daha öncede verdiğimiz örnekten yola çıkarak orman içerisindeki insanları tespit etmek ve etiketlemek istediğimizi düşünelim, etiketleme kavramını nesnenin ne olduğunu belirtmek anlamında kullandığımı da belirtmekte fayda var. Bir algoritmada karar kıldık örnek verilerden yola çıkarak sonucun başarılı olacağına karar verdik ve test için hazir hale getirdik. Fakat test için verilen girdilerde fotoğraf makinesi kaynaklı oluşmuş piksel bozuklukları olduğunu düşünelim bu durumda sonuç beklediğimiz gibi çıkar mı? Ayni sekilde verilen bir görüntüde çekim açısından kaynaklanan parlakliklar var ve görüntüyü bozuyor, bu durumda düzgün veri hazırlamayan kullanıcıyı mı, yoksa algoritmanın bu hataları farkedemeyecek kadar kötü olduğunu düşünerek algortimayimi suclsmaliyiz. Tabiki de hayır burada yapılması gereken şey bu gibi durumlara önlem almadığımız için kendimizi suclayabiliriz. Peki ne yapmalıyız?
Veri ön işlemenin nedenlerini siralamak gerekirse; gürültülü parazitli veriler, tam olmayan eksik veriler ve tutarsız veriler olarak sayabiliriz. Peki bunlari nasıl yapabiliriz?
Veri ön işleme için bir çok algortima veya yöntem mevcuttur, bu yöntemler insan gözü ile denetleme olabileceği gibi karmaşık sinir ağları bile olabilir. Bu yöntemleri de siralamak istersek; Regresyon, esikleme, kümeleme, filtreleme, binnig, karar ağaçları vb. diyebiliriz. Unutulmaması gereken bir diğer nokta ise bazılen tek başına bir yöntemi uygulamak yeterli gelmeyebilir, bu durumlarda bir kaç farklı yöntemi peş peşe kullanabiliriz.
 Gürültülü bir fotoğraf ve ön işlem sürecinin ardından oluşturulmuş yeni hali (Lena).
Gürültülü bir fotoğraf ve ön işlem sürecinin ardından oluşturulmuş yeni hali (Lena).
4. Öznitelik
Bu aşamada ön işleme tabi tutulmuş veri üzerinde daha önceden belirlenen nesnenin/isterin elde edilmesidir. Bu bölümde öznitelik çıkarma (feature extraction) kavramına değinmek gerekiyor. Feature extraction; “Detay çıkarma: Bir cismin önceden tanımlanmış kriterleri ve özellikleri sayesinde görüntüler üzerinden otomatik olarak tespit edilmesi ve detaylarının elde edilmesi işlemi; eşanlam: detay saptama.” ve “Öznitelik çıkarma: Örüntü tanıma ve istatistiksel işaret işlemede, sınıflandırma amacıyla alınan ölçümlerin bazı dönüşümlerle daha özlü, daha az gürültülü, daha az sayıda ayırt edici değerlere dönüştürülmesi.” Bu tanımı bazı kaynaklarda özellik çıkarımı olarak da görebilirsiniz.
Bir örnekle durumu anlaşılır hale getirelim. Yukarıdada değindiğimiz bir örnek vardı; orman içerisindeki insanları tespit etmek. Bu aşmada her nesneye özel bir öznitelik çıkarımı tanımlamak gerekebilir. Örneğimize dönecek olursak, ormandaki bir insanı nasıl ayırt edebilir? Ağaçlar yeşildir ve belirli bir formu vardır bunu tanımlayıp dışında kalanlara insan diyebilir miyiz? Duruma göre belki evet ama genel olarak cevap hayır. İnsan vücudunun sabit bir formu var peki bunu tanımlasak nasıl olur? İnsanın 2 adet ayağı bu ayak zeminin hemen üzerinde bir birlerine paral olabilir diyebilir miyiz? Evet diyebilir ama zemini de tanımlamamız gerekiyor. Gördüğünüz gibi çok fazla tanımlamamız gerek şey var. Bunları tek tek matematiksel olarak tanımlayabileceğimiz gibi algoritmaya öğretebiliriz de, bu ihtiyaca ve probleme göre değişkenlik gösteren bir durum.
Bu işlemler sonunda elde edeceğimiz şey , istediğimiz nesnenin görüntü üzerine var mı, varsa nerede olduğudur. Peki bu yöntemler nedir? Öznitelik çıkarımı için kullanabileceğiniz yüzlerce algoritma var kısaca bir kaçını saymak gerekirse SIFT (Scale-Invariant Feature Transform), SURF (Speeded-Up Robust Features), Feature Matching, Haar Cascades, HOG (Histogram of Oriented Gradients) vb. diyebiliriz.
5. Tanımlama
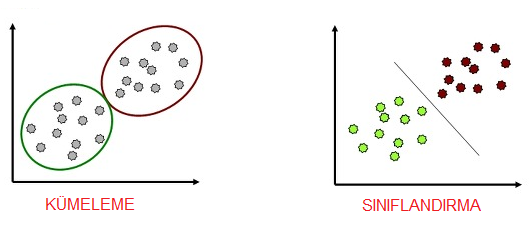
Tanımlama, tespit ettiğimiz görüntüden çıkarım yapabilmek, tanımak yani bu görüntünün ne olduğunu anlama aşaması olarak basitce tanımlanabilir. Bu bölümde temek iki kavrama değinmek gerekiyor; Sınıflandırma ve Kümeleme. Sınıflandırma veriyi önceden belirlenmiş sınıflardan birine dahil etmektir. Danışmanlı (Gözetimli, Supervised) öğrenme, kestirim ve örüntü tanıma yöntemleri ile gerçekleştirilir. Kümelemede ise benzer verileri, benzer özellik gösterenler aynı grupta toplanırlar.
Referanslar
- [https://www2.units.it/carrato/didatt/EI_web/slides/ti/72_ViolaJones.pdf](https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf)
- https://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html
- http://www.tubaterim.gov.tr/ (feature extraction)